Performance regression in combine_first() #6557
Comments
|
I think this is just related to the indexing that was fixed in regards to the non-daily caching (don't remember the issue). In master this looks fine. |
|
Sorry about that, looks like my kernel didn't pick up the build from HEAD. |
|
np keep reporting! |
|
Ok, so the performance regression does exist but I don't think it's a bug. This test case reproduces the regression (yes, it's ugly and un-idiomatic): from pandas.tseries.offsets import MonthEnd
from pandas import *
rows = 2000
s = Series(np.random.random(rows), index=DatetimeIndex(start='1/1/1900', periods=rows, freq='M'))
s = s.reindex(s.index.append(DatetimeIndex([s.index[-1] + MonthEnd()])))
a = s.copy()
s.ix[-500:] = float('nan')
print s.index._can_fast_union(s.index)
print s.index.offset
%timeit s.combine_first(a)Unlike However, if you do which is just incorrect given If you put My guess is that a caching mechanism went and inferred the frequency and set So performance regression isn't a bug, though |
I took another look at the testing that lead to #6479 and am still seeing ~73% slowdown. Benchmarking my application with v0.12.0 against 549a390 found a 48x slowdown in
Series.combine_firstwhen using aDatetimeIndexwithMonthEndoffsets. This is also present in v0.13.1, so it wasn't introduced by the fix to #6479 . The test case:And the comparison:
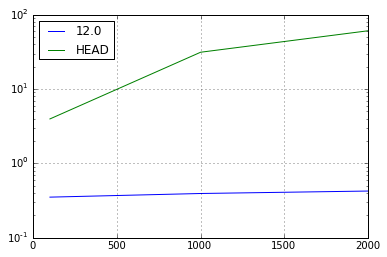
This regression does not exist for daily indices. Probably also exists for DataFrames and other offset frequencies. I'll create some vbenches later.
The text was updated successfully, but these errors were encountered: